
This is a collaborative research piece written by SQD & Barter.
DeFi was designed around a specific actor: a human being with a browser, intermittent attention, and a reasonable tolerance for things going slightly wrong. Slippage tolerance defaults exist because humans can't react in milliseconds. Confirmation prompts exist because humans misclick. Liquidity pools lock capital because humans don't mind - they'll check back on Thursday.
That actor is being replaced.
Autonomous agents don't browse. They execute. They don't tolerate latency - they price it. They don't set a range and forget it - they optimise continuously across every available opportunity, compressing weeks of human decision-making into a single block. And unlike the retail trader who shrugs off a bad fill, an agent treats every inefficiency as a direct, recurring deduction from its objective function.
The problem isn't that agents are new. The problem is that every layer of DeFi infrastructure still assumes the old actor. The data layer was built for humans who query occasionally. The routing layer was built for humans who click once and wait. The liquidity layer was built for humans who accept lock-up as the price of participation. None of these assumptions hold at agent scale - and the costs of getting it wrong don't add up linearly. They compound.
This article maps three layers where that compounding happens: data, routing, and liquidity. SQD and Barter sit at the foundation of two of them. What follows isn't a pitch - it's a technical accounting of what breaks, what it costs, and what infrastructure actually designed for autonomous agents looks like.
The shift has already started. The question is whether the infrastructure catches up before the losses do.
A new entity of market participant
For two decades, financial infrastructure has been designed around a single assumption: the end-user is a human being, interfaces are visual. Confirmation prompts exist because people make mistakes. Slippage tolerances are wide because humans can't react in sub-second windows. Every design decision - from how liquidity pools work to how gas estimation defaults are set - carries the implicit fingerprint of human cognition: slow, error-prone, intermittent, and emotional.
Autonomous agents break every one of these assumptions.
An agent doesn't "check its portfolio" once a day. It evaluates state every block. It doesn't tolerate 2% slippage - it treats every basis point of unnecessary slippage as a direct deduction from its objective function. It doesn't leave capital idle in an LP position while a better opportunity emerges on another venue, because it has no concept of convenience or habit.
We're talking about a regime change in what "participation" means. Consider the contrast across five core dimensions:
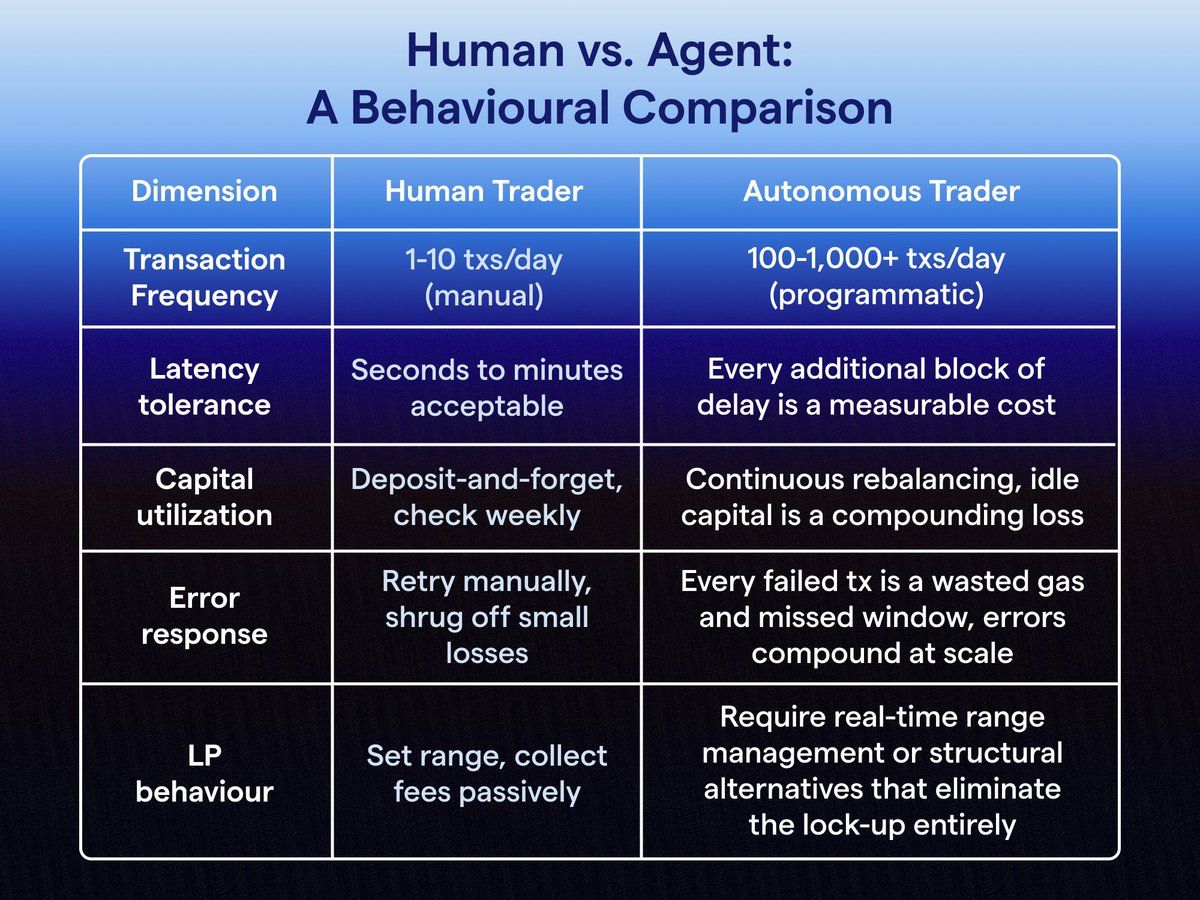
At human scale, each inefficiency is a rounding error. At agent scale, they compound. An agent executing 500 swaps per day at 0.3% average excess slippage bleeds 1.5% of daily volume - silently, continuously, structurally. A failed transaction that costs a human $0.50 in gas costs an agent fleet $0.50 × 500 retries × 30 days = $7,500/month. Bad UX isn't just annoying for agents. It's a P&L line item.
The infrastructure that DeFi built for humans doesn't merely underperform for agents - it actively penalises them. What follows is an examination of exactly where those penalties accumulate, starting with the most fundamental operation an agent performs: routing a swap.
Routing at agent scale
When a human trader executes a swap on a DEX frontend, routing is invisible. The UI picks a path, shows a price, the user clicks "Swap". Whether the trade was split across two pools or seven, whether 12% of volume was routed through a secondary venue to reduce price impact - none of this surfaces. At one swap per hour, it doesn't need to.
At agent scale, routing is everything. An autonomous agent operating at 500+ swaps per day is not casually browsing a token page. It is systematically executing a strategy where every basis point of execution quality directly determines whether the strategy is profitable. And the reality of onchain liquidity in 2025-2026 is that it is deeply fragmented.
On Ethereum mainnet alone, meaningful liquidity for a major pair like ETH(WETH)/USDC is split across Uniswap v3, Uniswap v4 hooks pools, Curve, Balancer, SushiSwap, Maverick, Ambient, and a growing tail of PMMs (private market makers). On L2s, the fragmentation multiplies: Arbitrum, Base, Optimism each have their own liquidity topology. A naive single-venue swap leaves value on the table. A poorly optimised split-route leaves less value on the table, but still measurably more than a properly optimised one.
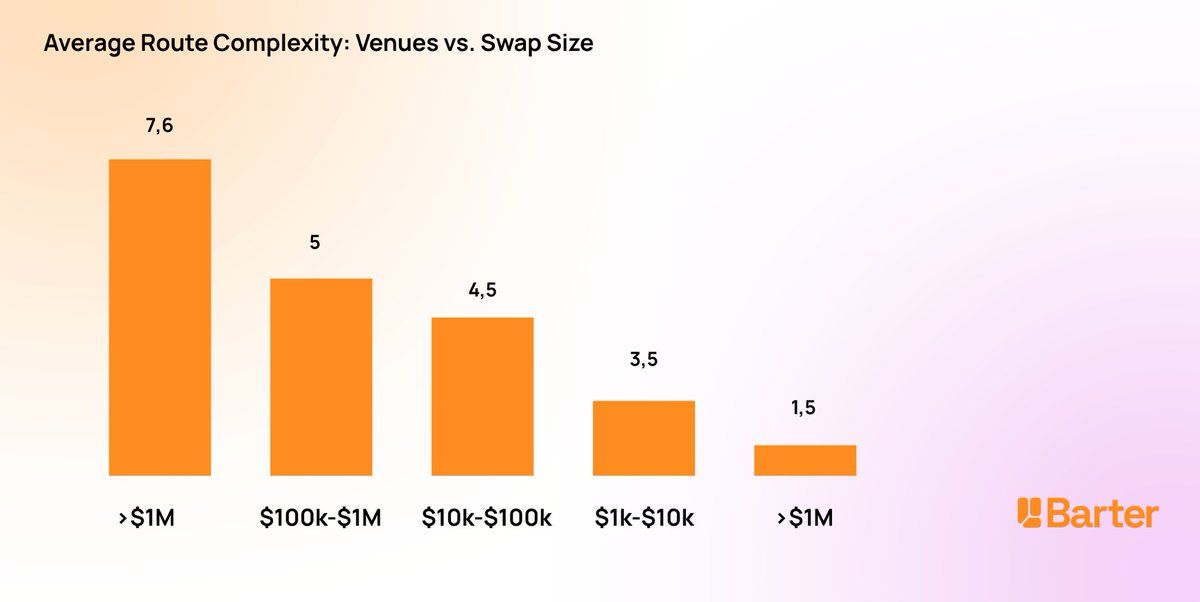
How route complexity scales with trade size
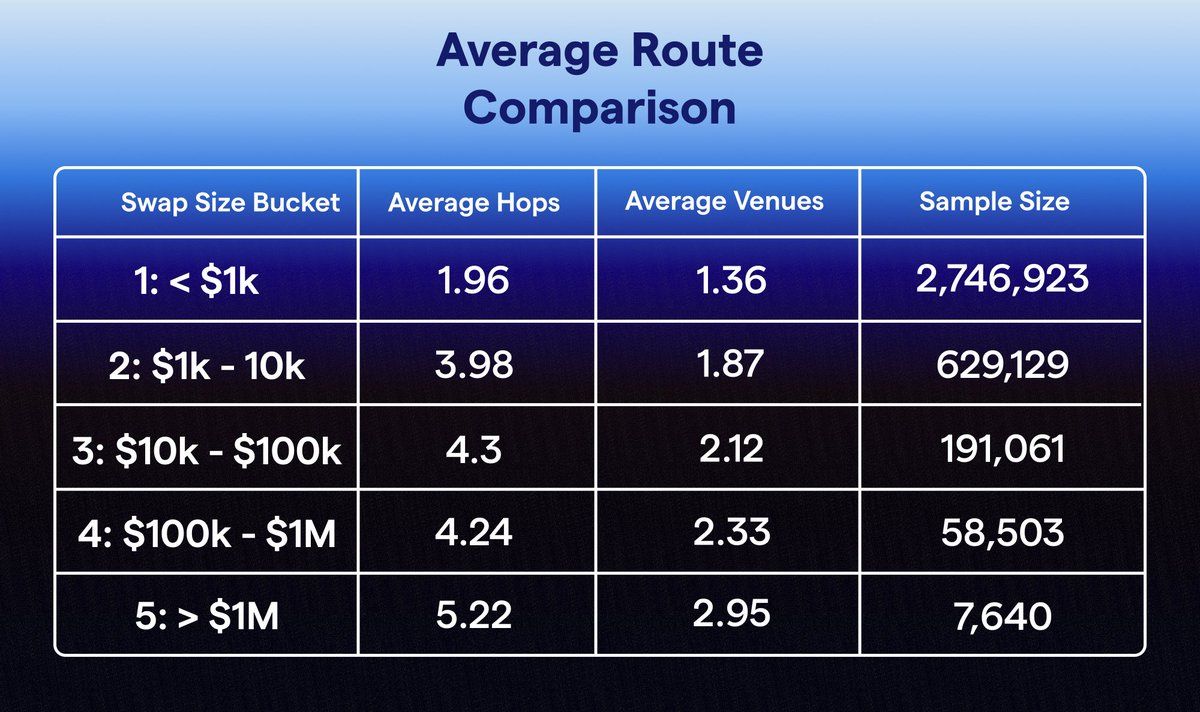
The relationship between swap size and optimal route complexity is non-linear. Small swaps ($100-$1K) are almost always best served by a single pool - the gas overhead of splitting outweighs the price improvement. But as trade size grows, the optimal strategy shifts sharply:
- $1K-$10K: 3-4 venues, rarely more. The primary pool absorbs the order with minimal impact.
- $10K-$100K: 4-5 venues become standard. Price impact on any single pool starts to exceed the gas cost of a split route.
- $100K-$1M: 4-6 venues, with non-trivial percentage allocations to secondary and tertiary sources. Direct routing through a single venue can cost 50-200 bps in price impact.
- $1M+: 5-10+ venues, often including intermediate hops (e.g., ETH → USDT → target token) where the direct pair has insufficient depth. Route optimisation at this tier is computationally intensive and time-sensitive - liquidity states change block by block.
For an agent, this means that routing quality isn't a convenience feature - it's base infrastructure. And the traditional mechanism of accessing routing (a browser-based frontend with a "swap" button) doesn't even expose the control surface they need. Agents require programmatic access: an API that accepts parameters (input token, output token, amount, slippage constraints, venue exclusions, gas budget) and returns an optimised execution plan. This is what every router will provide in future - a routing primitive designed for programmatic consumption.
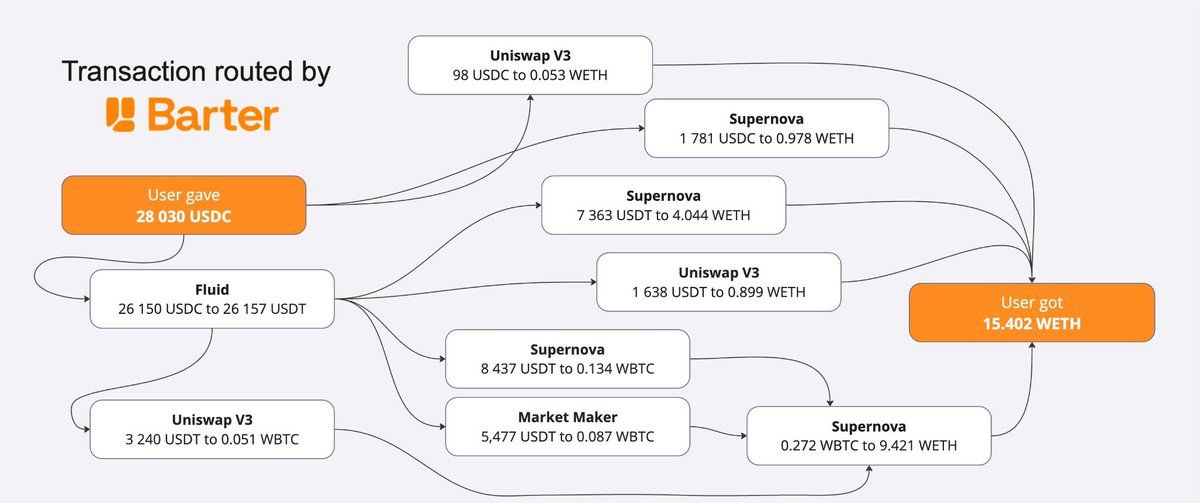
Liquidity and yield: why locked capital kills agent returns
Before we even talk about LP mechanics, look at the bigger picture. The vast majority of stablecoins in DeFi aren't doing anything at all. Wallets hold nearly 6× more stablecoins than DEXs, lending protocols, and bridges combined. Tens of billions in USDC, USDT, and DAI sit in EOAs and smart contract wallets, earning zero yield, providing zero liquidity, participating in zero markets.
The LP model that dominates DeFi today - deposit tokens into a pool, earn fees proportional to your share - was designed for passive participants. A human deposits ETH/USDC into Uniswap v3, sets a price range, and checks back in a week. The capital is locked and the range might drift out of bounds. The fees earned might not cover the gas spent rebalancing. But for the human, this is "set and forget" investing - the cognitive overhead is low, and the alternative (active management) feels like a job.
The current model forces a binary choice: either deposit your capital into a protocol and lose control of it, or keep it in your wallet and accept that it's inert. But for an agent, every aspect of this model is structurally wrong.
The three taxes on agent LP capital
Tax 1: Out-of-range idle time. Concentrated liquidity positions only earn fees when the market price sits within the deposited range. Empirical data on Uniswap v3 shows that for typical ±5% ranges on volatile pairs, positions spend 30-60% of their lifetime out of range, earning zero. For an agent, this isn't acceptable drift - it's capital allocated to a yield strategy that yields nothing for a third to half of its deployment time.
Tax 2: Gas overhead. Managing a concentrated liquidity position requires constant rebalancing: withdrawing, redepositing at a new range, compounding fees. Each operation costs gas. On Ethereum mainnet, a full rebalance cycle can cost $2-$5 depending on gas prices.
Tax 3: Opportunity cost. This is the silent killer. Capital locked in an LP position cannot simultaneously be used for anything else. If a lending rate spike occurs on Aave, if an arbitrage window opens on another pair, if a liquidation opportunity appears, the LP capital is inaccessible. For a human managing one or two positions, this is abstract. For an agent optimising across dozens of opportunities per hour, locked capital is a hard constraint on strategy space. The yield is APY minus gas minus the best alternative return that capital could have captured during the same period. When you calculate it this way, most LP positions for agents are net-negative.
Superposition: liquidity without lock-up
Superposition introduces a fundamentally different primitive. Instead of depositing tokens into a pool contract, a liquidity provider grants an allowance - the protocol can access the tokens for matching trades, but the tokens remain in the provider's wallet. It is a structural change in how capital commitment works.
For an agent, Superposition means:
- No idle capital. The same tokens that are providing liquidity can simultaneously serve as collateral, be available for arbitrage, or back a lending position. The capital is committed to liquidity provision without being locked.
- No rebalancing gas. Because liquidity exposure is managed via allowance parameters rather than discrete deposit/withdraw cycles, the gas cost of position management drops by an order of magnitude.
- Real composability. An agent can layer strategies - the same ETH providing liquidity on Superposition remains available for instant deployment if a high-value opportunity appears. These aren't hypothetical - they're the natural behaviour of any economic agent that isn't constrained by lock-up mechanics.
Data errors don't scale linearly
Routing quality and liquidity efficiency are both bounded by the same upstream constraint: the data feeding the decision engine. At agent scale, that dependency stops being an abstract concern and becomes a quantifiable P&L liability.
The human baseline
A human encountering bad data has a natural circuit breaker: suspicion. A price that looks off gets double-checked. The decision loop is slow enough that stale data is usually caught before it costs anything material. When it isn't, the loss is a one-time event.
An agent has no suspicion reflex. At 500 decisions per day, there's no manual review step between data ingestion and action. If the data layer is wrong, the agent is wrong - continuously, systematically, and at scale.
How errors compound
The critical distinction isn't frequency - it's feedback architecture. When a human makes a bad trade on stale data, it's an isolated event. When an agent does, it updates its internal state based on that outcome and feeds it into the next decision. The error doesn't affect one swap. It contaminates the chain.
Indexing lag on most existing infrastructure runs 2-3 blocks behind chain tip - around 24-36 seconds on Ethereum mainnet. For an agent executing time-sensitive arbitrage or a rebalance triggered by a price threshold, that's the entire window. But missed opportunity is only part of the cost. An agent that acts on a stale liquidity snapshot or a missed large-trade event executes a strategy that was never valid. At 500 swaps/day with even 0.5% systematic execution degradation from data quality, that's 250bps of daily volume lost to infrastructure failure - not strategy failure.
What SQD changes
SQD's architecture delivers sub-block data freshness - processing and serving state at chain tip rather than batching after block confirmation. The agent sees what the chain sees, when the chain sees it.
The downstream effects are concrete: backtests built on accurate historical data produce models that generalise to live conditions; liquidation monitoring catches position health changes before the window closes; LP logic doesn't enter ranges already invalidated by recent trades.
The data layer is the precondition for everything above it. SQD exists to make sure that ceiling is as high as it can be.
The full loop
DeFi doesn't fail at the edges. It fails in the loop. Data feeds decisions. Decisions flow into routing. Routing hits liquidity. Execution writes a new state back onchain, and the cycle repeats. At human scale, breaks inside this loop are survivable. At agent scale, they are multiplicative.
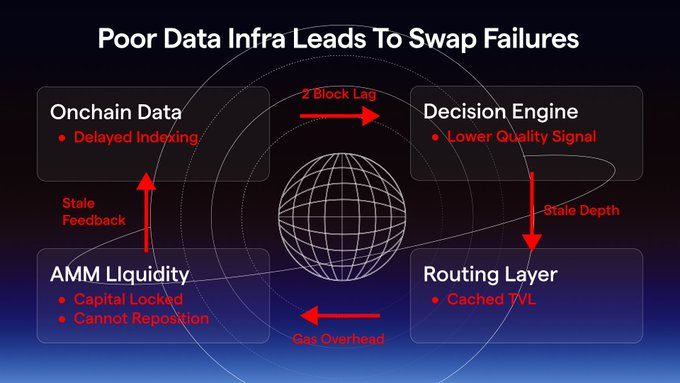
The first diagram shows what happens when even one layer lags behind the actor. A two-block delay in data propagates into a lower-quality decision. The router operates on stale depth, liquidity cannot reposition, gas overhead accumulates - the system doesn't collapse at a single point, it degrades across the entire loop.
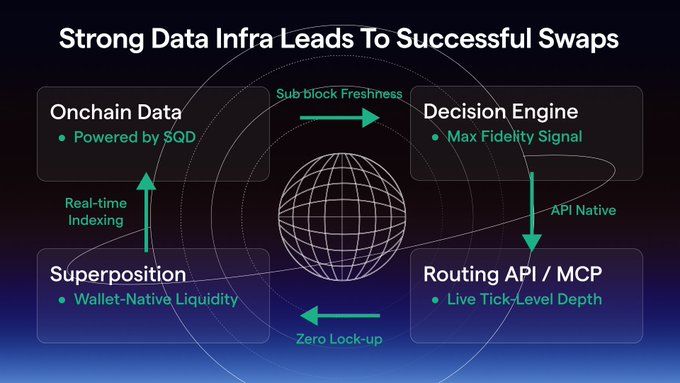
The second diagram shows the same loop, but aligned with the actor. Sub-block data removes informational lag. The decision engine operates on maximum-fidelity signals. Routing becomes API-native and reacts to live market depth. Liquidity is no longer locked, but dynamically exposed from the wallet, eliminating idle capital and enabling instant reallocation. The loop holds.
This is where SQD, Barter, and Superposition converge. DeFi doesn't need incremental improvements. It needs infrastructure that assumes the right actor.
Because in a system where capital is autonomous, every broken loop is a tax - and every fixed loop is edge.